📝 题目描述
题目链接:二叉搜索树中第 K 小的元素
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 小的元素(k 从 1 开始计数)。
示例:
示例 1:
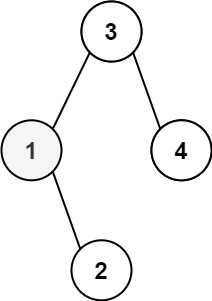
1
2
| 输入:root = [3,1,4,null,2], k = 1
输出:1
|
示例 2:
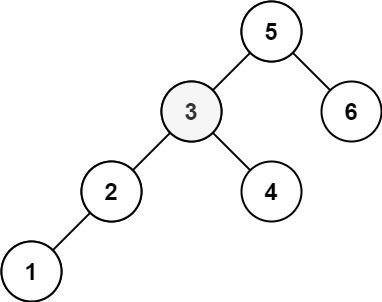
1
2
| 输入:root = [5,3,6,2,4,null,null,1], k = 3
输出:3
|
提示:
树中的节点数为 n1 <= k <= n <= 10^40 <= Node.val <= 104
💡 解题思路
方法一:中序遍历
还记得“将有序数组转换为二叉搜索树”吗?在这里面我们提到:
二叉搜索树的中序遍历得到的值构成的序列一定是升序的。
据此,我们可以对题目中的二叉树进行中序遍历,第 k 个值就是我们要找的答案。
★方法二:记录子树的结点数
在方法一中,我们之所以需要中序遍历前 k 个元素,是因为我们不知道子树的结点数量,不得不通过遍历子树的方式来获知。
因此,我们可以记录下以每个结点为根结点的子树的结点数,并在查找第 k 小的值时,使用如下方法搜索:
-
令 node 等于根结点,开始搜索。
-
对当前结点 node 进行如下操作:
- 如果
node 的左子树的结点数 left 小于 k−1,则第 k 小的元素一定在 node 的右子树中,令 node 等于其的右子结点,k 等于 k−left−1,并继续搜索;
- 如果
node 的左子树的结点数 left 等于 k−1,则第 k 小的元素即为 node ,结束搜索并返回 node 即可;
- 如果
node 的左子树的结点数 left 大于 k−1,则第 k 小的元素一定在 node 的左子树中,令 node 等于其左子结点,并继续搜索。
在实现中,我们既可以将以每个结点为根结点的子树的结点数存储在结点中,也可以将其记录在哈希表中。
🔧 代码实现
1、中序遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
class Solution {
public:
int kthSmallest(TreeNode* root, int k) {
stack<TreeNode*> st;
TreeNode* ptr = root;
while(!st.empty() || ptr != nullptr) {
if (ptr) {
st.push(ptr);
ptr = ptr -> left;
} else {
ptr = st.top(); st.pop();
k--;
if (k == 0) {
return ptr -> val;
}
ptr = ptr -> right;
}
}
return -1;
}
};
|
2、记录子树的结点数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| class MyBst {
public:
MyBst(TreeNode *root) {
this->root = root;
countNodeNum(root);
}
int kthSmallest(int k) {
TreeNode *node = root;
while (node != nullptr) {
int left = getNodeNum(node->left);
if (left < k - 1) {
node = node->right;
k -= left + 1;
} else if (left == k - 1) {
break;
} else {
node = node->left;
}
}
return node->val;
}
private:
TreeNode *root;
unordered_map<TreeNode *, int> nodeNum;
int countNodeNum(TreeNode * node) {
if (node == nullptr) {
return 0;
}
nodeNum[node] = 1 + countNodeNum(node->left) + countNodeNum(node->right);
return nodeNum[node];
}
int getNodeNum(TreeNode * node) {
if (node != nullptr && nodeNum.count(node)) {
return nodeNum[node];
}else{
return 0;
}
}
};
class Solution {
public:
int kthSmallest(TreeNode* root, int k) {
MyBst bst(root);
return bst.kthSmallest(k);
}
};
|
📊 复杂度分析
1、中序遍历
- 时间复杂度:O(H+k),其中 H 是树的高度。在开始遍历之前,我们需要 O(H) 到达叶结点。当树是平衡树时,时间复杂度取得最小值 O(logN+k);当树是线性树(树中每个结点都只有一个子结点或没有子结点)时,时间复杂度取得最大值 O(N+k)。
- 空间复杂度:O(H),栈中最多需要存储 H 个元素。当树是平衡树时,空间复杂度取得最小值 O(logN);当树是线性树时,空间复杂度取得最大值 O(N)。
2、记录子树的结点数
- 时间复杂度:预处理的时间复杂度为 O(N),其中 N 是树中结点的总数;我们需要遍历树中所有结点来统计以每个结点为根结点的子树的结点数。搜索的时间复杂度为 O(H),其中 H 是树的高度;当树是平衡树时,时间复杂度取得最小值 O(logN);当树是线性树时,时间复杂度取得最大值 O(N)。
- 空间复杂度:O(N),用于存储以每个结点为根结点的子树的结点数。
🎯 总结