LeetCode47 - 从前序与中序遍历序列构造二叉树
📝 题目描述
题目链接:从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的 先序遍历, inorder 是同一棵树的 中序遍历,请构造二叉树并返回其根节点。
示例:
示例 1:
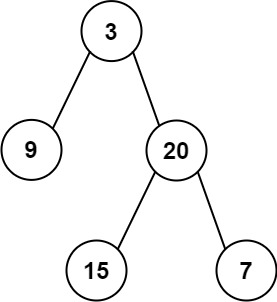
1 | 输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7] |
示例 2:
1 | 输入: preorder = [-1], inorder = [-1] |
提示:
1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorder 和 inorder 均 无重复 元素inorder 均出现在 preorderpreorder 保证 为二叉树的前序遍历序列inorder 保证 为二叉树的中序遍历序列
💡 解题思路
方法一:递归
对于任意一颗树而言,前序遍历的形式总是:
1 | [ 根节点, [左子树的前序遍历结果], [右子树的前序遍历结果] ] |
即根节点总是前序遍历中的第一个节点。
而中序遍历的形式总是
1 | [ [左子树的中序遍历结果], 根节点, [右子树的中序遍历结果] ] |
只要我们在中序遍历中 定位 到根节点,那么我们就可以分别知道左子树和右子树中的节点数目。由于同一颗子树的前序遍历和中序遍历的长度显然是相同的,因此我们就可以对应到前序遍历的结果中,对上述形式中的所有左右括号进行定位。
这样以来,我们就知道了左子树的前序遍历和中序遍历结果,以及右子树的前序遍历和中序遍历结果,我们就可以递归地对构造出左子树和右子树,再将这两颗子树接到根节点的左右位置。
★方法二:迭代
思路:
迭代法是一种非常巧妙的实现方法。
对于前序遍历中的任意两个连续节点 和 ,根据前序遍历的流程,我们可以知道 和 只有两种可能的关系:
- 是 的左儿子。这是因为在遍历到 之后,下一个遍历的节点就是 的左儿子,即 ;
- 没有左儿子,并且 是 的某个祖先节点(或者 本身)的右儿子。如果 没有左儿子,那么下一个遍历的节点就是 的右儿子。如果 没有右儿子,我们就会向上回溯,直到遇到第一个有右儿子(且 不在它的右儿子的子树中)的节点 ,那么 就是 的右儿子。
第二种关系看上去有些复杂。我们举一个例子来说明其正确性,并在例子中给出我们的迭代算法。
例子:
我们以树
1 | 3 |
为例,它的前序遍历和中序遍历分别为
1 | preorder = [3, 9, 8, 5, 4, 10, 20, 15, 7] |
我们用一个栈 stack 来维护“当前节点的所有还没有考虑过右儿子的祖先节点”,栈顶就是当前节点。也就是说,只有在栈中的节点才可能连接一个新的右儿子。同时,我们用一个指针 index 指向中序遍历的某个位置,初始值为 0。index 对应的节点是“当前节点不断往左走达到的最终节点”,这也是符合中序遍历的,它的作用在下面的过程中会有所体现。
首先我们将根节点 3 入栈,再初始化 index 所指向的节点为 4,随后对于前序遍历中的每个节点,我们依次判断它是栈顶节点的左儿子,还是栈中某个节点的右儿子。
-
我们遍历
9。9一定是栈顶节点3的左儿子。我们使用反证法,假设9是3的右儿子,那么3没有左儿子,index应该恰好指向3,但实际上为4,因此产生了矛盾。所以我们将9作为3的左儿子,并将9入栈。stack = [3, 9]index -> inorder[0] = 4
-
我们遍历
8,5和4。同理可得它们都是上一个节点(栈顶节点)的左儿子,所以它们会依次入栈。stack = [3, 9, 8, 5, 4]index -> inorder[0] = 4
-
我们遍历
10,这时情况就不一样了。我们发现index恰好指向当前的栈顶节点4,也就是说4没有左儿子,那么10必须为栈中某个节点的右儿子。那么如何找到这个节点呢?栈中的节点的顺序和它们在前序遍历中出现的顺序是一致的,而且每一个节点的右儿子都还没有被遍历过, 那么这些节点的顺序和它们在中序遍历中出现的顺序一定是相反的。
这是因为栈中的任意两个相邻的节点,前者都是后者的某个祖先。并且我们知道,栈中的任意一个节点的右儿子还没有被遍历过,说明后者一定是前者左儿子的子树中的节点,那么后者就先于前者出现在中序遍历中。
-
因此我们可以把
index不断向右移动,并与栈顶节点进行比较。如果index对应的元素恰好等于栈顶节点,那么说明我们在中序遍历中找到了栈顶节点,所以将index增加1并弹出栈顶节点,直到index对应的元素不等于栈顶节点。按照这样的过程,我们弹出的最后一个节点x就是10的双亲节点, 这是因为10出现在了x与x在栈中的下一个节点的中序遍历之间,因此10就是x的右儿子。 -
回到我们的例子,我们会依次从栈顶弹出
4,5和8,并且将index向右移动了三次。我们将10作为最后弹出的节点8的右儿子,并将10入栈。stack = [3, 9, 10]index -> inorder[3] = 10
-
我们遍历
20。同理,index恰好指向当前栈顶节点10,那么我们会依次从栈顶弹出10,9和3,并且将index向右移动了三次。我们将20作为最后弹出的节点3的右儿子,并将20入栈。stack = [20]index -> inorder[6] = 15
-
我们遍历
15,将15作为栈顶节点20的左儿子,并将15入栈。stack = [20, 15]index -> inorder[6] = 15
-
我们遍历
7。index恰好指向当前栈顶节点15,那么我们会依次从栈顶弹出15和20,并且将index向右移动了两次。我们将7作为最后弹出的节点20的右儿子,并将7入栈。stack = [7]index -> inorder[8] = 7
此时遍历结束,我们就构造出了正确的二叉树。
算法:
我们归纳出上述例子中的算法流程:
- 我们用一个栈和一个指针辅助进行二叉树的构造。初始时栈中存放了根节点(前序遍历的第一个节点),指针指向中序遍历的第一个节点;
- 我们依次枚举前序遍历中除了第一个节点以外的每个节点。如果
index恰好指向栈顶节点,那么我们不断地弹出栈顶节点并向右移动index,并将当前节点作为最后一个弹出的节点的右儿子;如果index和栈顶节点不同,我们将当前节点作为栈顶节点的左儿子; - 无论是哪一种情况,我们最后都将当前的节点入栈。
最后得到的二叉树即为答案。
🔧 代码实现
1、递归
1 | /** |
2、迭代
1 | class Solution { |
📊 复杂度分析
1、递归
- 时间复杂度:,其中 n 是树中的节点个数。
- 空间复杂度:,除去返回的答案需要的 空间之外,我们还需要使用 的空间存储哈希映射,以及 (其中 h 是树的高度)的空间表示递归时栈空间。这里 ,所以总空间复杂度为 。
2、迭代
- 时间复杂度:,其中 n 是树中的节点个数。
- 空间复杂度:,除去返回的答案需要的 空间之外,我们还需要使用 (其中 h 是树的高度)的空间存储栈。这里 ,所以(在最坏情况下)总空间复杂度为 。
🎯 总结
- 核心思想:分治法注意边界条件,保持一直左闭右开。